Stage 1 - Creating H Slices¶
H Slices¶
The footprint data from the netcdf footprint files is extracted for each receptor and placed in “H slice” files using the script hsplit.py
Prerequisites¶
There are three things that are required before running hsplit.py.
- Make sure a configuration file is created.
- Create a landmask for the region under study.
- Create a receptor file with a list of footprint filenames to use.
Usage¶
hsplit.py is run with:
python hsplit.py [-c configfile] receptor_file where receptor_file : file containing footprint file names, 1 line per receptor -c configfile : configuration file. If not specified, use 'config.ini'. Required input files: landmask_na.npy - Landmask file
Description¶
The objective of hsplit.py is to extract the time-dependent non-zero footprint values from the netcdf footprint file, and store them in multiple files, one for each timestep used in the inversion. To minimize the amount of opening/closing of the footprint files, only one pass through the receptor list is done. Data from each footprint file is appended to intermediate text files. When the pass through the receptor list is completed, the text files are converted to numpy savez files (or optionally FORTRAN compatible binary files), containing the locations and values of non-zero footprint data. These ‘H strip’ files are sparse files, meaning that only the indices and values of non-zero grid cells are stored. The indices of the grid cells are dependent on the landmask that is being used, so that these indices can be converted to latitude and longitude if desired.
H slice files¶
Think of a single H strip file as an array of dimension nobs x nlandcells. Because we only want non-zero values in the files, instead of the full array we will save data as sparse arrays, only keeping the indices and non-zero values. Each line in the intermediate text files has three values, the observation number (i.e. the line number for the file in the receptor file, the land cell number, and the footprint value. These text files are converted to FORTRAN compatible binary files in hsplit.py. The format of the binary files consists of:
- a single 4 byte integer with the number of entries n,
- n 4 byte integers of observation numbers;
- n 4 byte integers of landcell numbers;
- and n 8 byte reals of footprint values.
We also need to know the size of the full, non-sparse array, so in the binary files the last entry will be the last observation number, the last landcell number, and either an actual obervation value or 0 if there is no observation value available. These values are required to be able to expand the sparse array into the fill non-sparse array, with 0’s for values of the missing data.
In the binary files, the observation numbers and land cell numbers are 1 based, i.e. they range from 1 to nobs, and from 1 to nlandcells respectively. In the intermediate text files, the observation numbers and cell numbers are 0 based, so they would range from 0 to nobs-1 and 0 to nlandcells-1.
Files are named Hnnnn.bin, where nnnn is the 0 padded timestep number, e.g. 0022.
Stage 2 - Applying Sprior sigma to H Slices and Calculating HQ¶
The modification that NOAA made to the method of Yadav and Michalak uses time and space varying values for 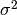 in equation 2.
in equation 2.
Define a vector 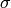 :
:
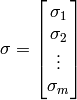
and a matrix 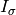 :
:
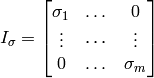
where m=p✕r = (number of time steps) ✕ (number of spatial grid cells).
Then
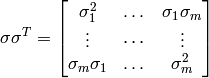
The prior error covariance is modeled with temporal decorrelation described by the p✕p matrix D and spatial decorrelation described by the r✕r matrix E such that:
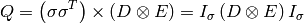
where 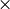 denotes element by element multiplication and
denotes element by element multiplication and 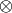 denotes the Kronecker product.
denotes the Kronecker product.
The modified algorithm for computing HQ is described by:
(1)![HQ = \left[\left( \left( \sum_{i=1}^{p} d_{i1}h_iI_{\sigma_i}\right)EI_{\sigma_1}\right) \left( \left( \sum_{i=1}^{p} d_{i2}h_iI_{\sigma_i}\right)EI_{\sigma_2}\right) ... \left( \left( \sum_{i=1}^{p} d_{iq}h_iI_{\sigma_i}\right)EI_{\sigma_q}\right)\right]](_images/math/d7383ce8e7501f53c7ab5053a27b4a0d6102c01e.png)
where the diagonal of 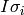 is the portion of the the vector corresponding to a single timestep
is the portion of the the vector corresponding to a single timestep 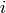 .
Compare to Equation (9) from Yadav and Michalak (2012).
The algorithm speed can be greatly improved if
.
Compare to Equation (9) from Yadav and Michalak (2012).
The algorithm speed can be greatly improved if 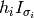 for each time step is pre-computed and retrieved as needed. We call this pre-computed Hsigma.
for each time step is pre-computed and retrieved as needed. We call this pre-computed Hsigma.
Hsigma¶
Hsigma requires multiplying the H strip for each timestep by the corresponding sigma values for that time step. The modified H strip is then saved for later use in the HQ calculations.
Sigma File Format¶
The format of the sigma file can be either a numpy .npy file with dimensions ntimesteps x nlandcells, or a netcdf file with a variable named ‘sigma’, with the dimensions ntimesteps x nlats x nlons. The lat and lon dimensions must match what is defined in the configuration file.
Example:
ncdump -h sigma.nc netcdf sigma { dimensions: dates = 92 ; lat = 70 ; lon = 120 ; variables: float dates(dates) ; string dates:long_name = "days since 2000-01-01" ; string dates:units = "days since 2000-01-01" ; double lat(lat) ; string lat:units = "degrees_north" ; string lat:long_name = "latitude" ; string lat:description = "latitude of center of cells" ; double lon(lon) ; string lon:units = "degrees_east" ; string lon:long_name = "longitude" ; string lon:description = "longitude of center of cells" ; float sigma(dates, lat, lon) ; string sigma:lonFlip = "longitude coordinate variable has been reordered via lonFlip" ; string sigma:long_name = "N2O emissions" ; string sigma:units = "nmolN2O/m2/s" ; sigma:time = 335.f ; string sigma:comment = "from CTlagrange/create_sprior_n2oES.ncl" ; sigma:_FillValue = 9.96921e+36f ; }
Usage¶
hsigma.py is run with:
python hsigma.py [-c configfile] sigmafile where sigmafile : file with sprior uncertainty values. Can be either a numpy save file of dimension ntimesteps x ncells, or a netcdf file with 'sigma' variable of dimensions ntimesteps x nlat x nlon configfile : configuration file. If not specified, use 'config.ini'. Required input files: H slice files
Output¶
hsigma.py creates another set of H slice files in the directory ‘Hsigma’, corresponding to the original H slice files.
HQ Calculations¶
The script hq.py is used to calculate the HQ part of equation 1. It requires for input the spatial distance array (see section Spatial Distances) and the hsigma slice files created with hsigma.py. Equation 2 uses a parameter lt for specifying the temporal covariance D. In the inversion code, a constant value of lt is used, and is defined in the configuration file with key name ‘temporal_corr_length’. The units for this value are in days.
Example:
temporal_corr_length = 7.0
The output from hq.py are HQ slice files, and 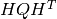 matrix from equation 1.
matrix from equation 1.
Usage¶
hq.py is run with:
Usage: hq.py [options] receptor_file sigma_file where receptor_file : file containing footprint file names, 1 line per receptor sigma_file : file with sprior uncertainty values. Can be either a numpy save file of dimension ntimesteps x ncells, or a netcdf file with 'sigma' variable of dimensions ntimesteps x nlat x nlon Options: -h, --help show this help message and exit -m MULTIPROCS, --multiprocs=MULTIPROCS Use multiple threads, e.g. --multiprocs=4. -c CONFIG, --config=CONFIG set configuration file to use. Default is 'config.ini' Required input files: hsigma slice files spcov.npy - spatial distance file Output HQ slice files HQHT array